End to End Learning for Autonomous Driving
End to End Learning for Self-Driving Cars by Mariusz Bojarski, Davide Del Testa, Daniel Dworakowski, Bernhard Firner, Beat Flepp, Prasoon Goyal, Lawrence D. Jackel, Mathew Monfort, Urs Muller, Jiakai Zhang, Xin Zhang, Jake Zhao, Karol Zieba
- What is the goal of the authors ?
- Methods
- Evaluation
- Interpretability
- Example Architecture :
- Challenges and Conclusion
- References
What is the goal of the authors ?
Addressing current approaches in End-to-End learning and showing it's potentials/challenges and training methods. Currently, the state of the art is based on modular architectures, where single tasks are learned and analyzed. While some of these modules might be learned, the interconnection between modules (for example bounding boxes as Perception stack outputs) is highly abstracted and therefore very limited. This offers several advantages such as easier debugging and better interpretability. Due to the number of taks that have already been solved with end-to-end learning, (chess, GO, DOTA2, ATARI games,...) it seems reasonable to think that end-to-end will be crucial in the near future. Especially since humans are able to control car while they are tired and/or distracted.
Methods
Imitation Learning (or behavior cloning)
Most dominant approach in end-to-end learning, where the goal it to mimic the behavior of an expert that teaches the system. The nature of this approach makes it simple to collect large amounts of data (Tesla Shadow mode for example). Complicated scenarios still remain a challenge $[1]$, as well as the distribution shift (data unseen during training) problem. Potential solutions to this are data augmentation, data diversification and on-policy learning. Futhermore it remains challenging to find cases that can be classified as anomalies and when a disengagement by the driver results in an actual edge case. Tesla described this challenge in some of their presentations, as it is important to evaluate wheter data by a specific driver is desirable or not.
Augmentation
In this scenario, augmentation in the image domain relates to the well known techniques (such as cropping, cutting, blurring, darkening/brightening, ...). Driving commands should be augmented correspondingly (steering angle has to be flipped when image is flipped left-right for example). Additionally, techniques such as binning and discarding data can be used to increase the dataset balance.
Diversification
During the data gathering process, diversifying should be one of the goals. Noise can also be added for further diversification of the data. This approach may allow for unseen scenarios to occur, but should be handled with care as it could lead to suboptimal behavior of the model during real world driving. Possible perubtations are shown below.
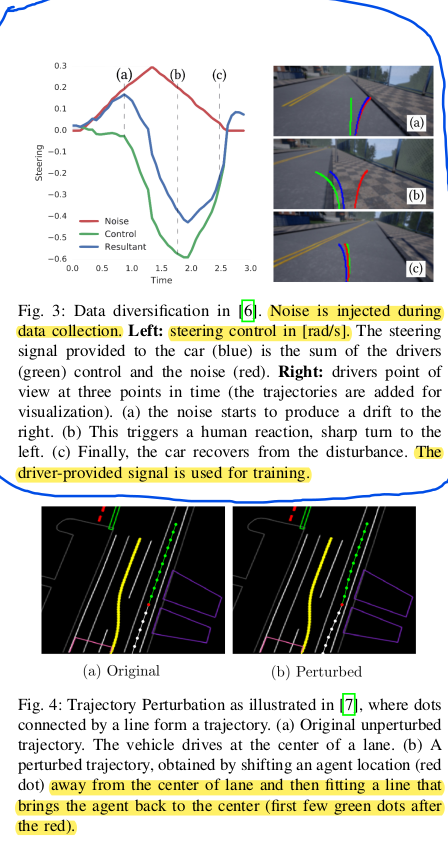 $[2][3]$
$[2][3]$
On-policy learning
Since decisions made by the autonomous agents can lead to the car drifing away from the optimal trajectory, DAgger $[4]$ proposes to switch between model and data during data collection. Essentially the expert trains the model to recover from mistakes that may occur during it's application. This also allows for question answering applications in case of uncertainty and allows for both offline or online annotations (SafeDAgger $[5]$). Researchers show that this sort of annotation can also be done by using a conventional localization stack during development.
As already mentioned, dataset inbalance is a problem due to both data frequency and data point difficulty. Sampling difficult datapoints more often during training might help the prediction error on these outliers. Nonetheless, this can lead to "easier" samples not being classified correctly anymore. Moreover, the non convex optimization problem of deep learning gives us no guarantee that the model will converge to the same minimum every time.
Reinforcement Learning
Since RL learns the driving policy through it's own experience, it is more immune to potentially insufficient data samples. This still remains a huge challenge as policies for the reward are difficult to create and increasinlgy more difficult to interpret with higher complexity. As learning in the real world can be challenging, it may be possible to improve IL models with RL experience and/or run an RL model on the car that runs on it while not taking control of the actuators. Outputs can then be compared with an IL model or interpreted for further deployment. The largest challenge of RL in the context of autonomous driving remains sim2real transfer, which would allow for experienced agents who were trained in simulation to be deployed in a real car.
Sim2real Transfer Learning
In order to reduce the impact of the sim2real gap, models can be retrained or even operate on data that abstracts from the real world (e.g. segmentation maps) $[6]$ this allows for training of the driving policy to be independet of the testing domain. Conidtional GANs can be used to generate real looking images from simulator data $[7]$, this data can then be used for model training.$[8]$ uses 2 autoencoders to map real world and simulation images to a shared lower dimensional latent space. The behavior of driving models and physcics models is not mentioned in the paper.
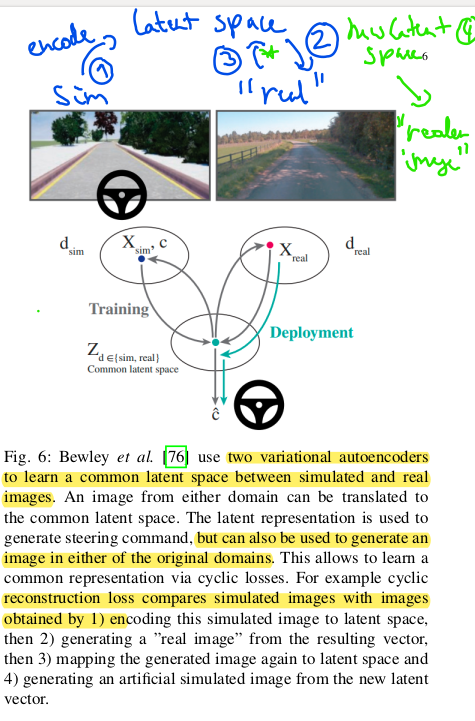
Inputs
Apart from sensor inputs by lidar, camera,imus, HD maps and other sensors should be used as inputs. Architectures that use map representations as input for end-to-end driving are also called mid-to-mid. Fused approaches are also possible, these might cooperate different sensors or timesteps. The use of semantic representations can lead to improved robustness of the model $[9]$. Using vehicle states such as speed and acceleration can lead to the inertia problem during imitation learning as shown in $[10]$. Navigational Inputs are mostly provided as commands or route planners, ChauffeurNet presents the following top-down map for this purpose :
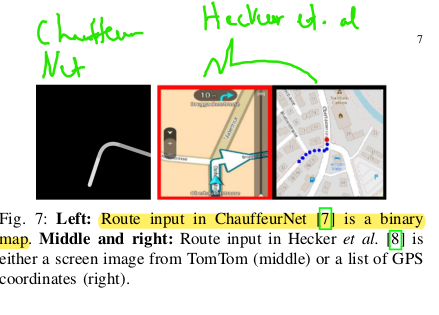
Optionaly text commands could be explored as mentioned by the authors. This may already be deployed in a L4 ride hailing service to some extent.
Outputs
Outputs can be traditional data such as steering and speed or waypoints or advanced representations like cost maps. These cost maps can be used to generate trajectories using optimization techniques like MPC. A representation of this is shown here :
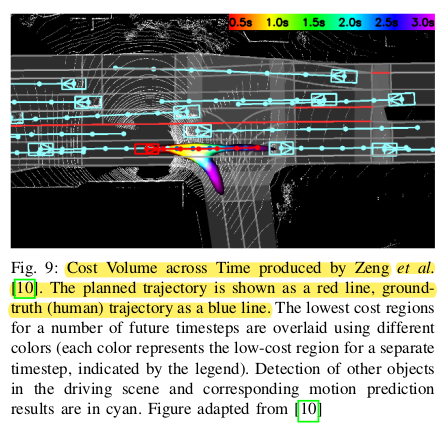
Frm the paprer :
"Direct perception $[10]$ approaches aim to fall between
modular pipelines and end-to-end driving and combine the
benefits of both approaches. Instead of parsing all the objects
in the driving scene and performing robust localization (as
modular approach), the system focuses on a small set of crucial
indicators, called affordances." This means that the pose of the car in lane and position of other objects relative to it are kown and then can be used to detect affordances in the way of the car :
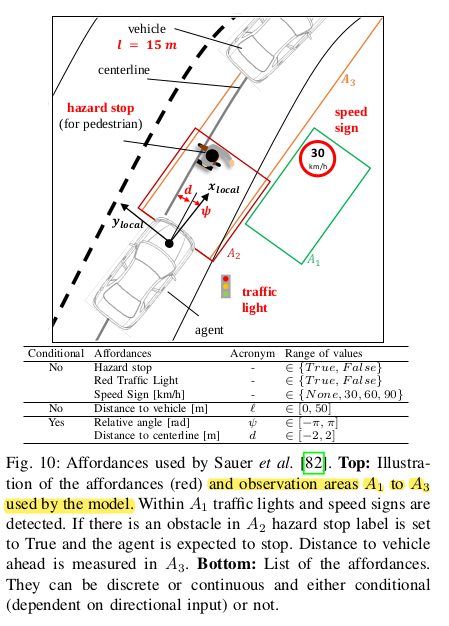
Mutlitask learning predicts multiple outputs at the same time, rich information exists within the layers, which can also be used for debugging and interpretation.
Evaluation
Since the models can not all be deployed in a real car, an evaluation strategy has to be adopted. In IL, open-loop evaluation can only be used while closed-loop is used for RL based techniques (easier to perform in simulation).
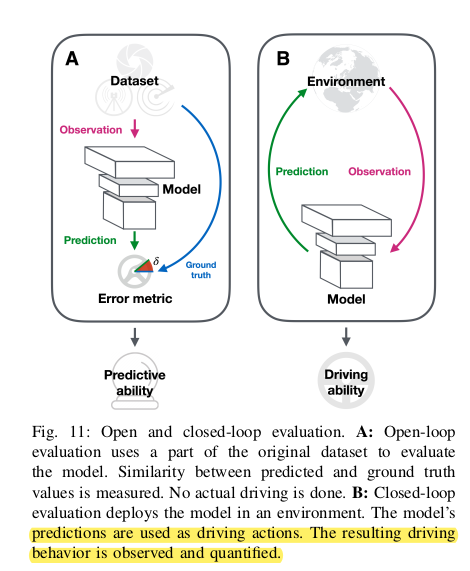
An example for error functions used :

The authors propose the following for the evaluation of different algorithms :
"For allowing to compare different end-to-end models, future
models should perform closed-loop evaluation:
• In diverse locations. Locations not used during training, if possible.
• In diverse weather and light conditions. Conditions not used during training, if possible.
• In diverse traffic situations, with low, regular or dense traffic.
If training the model in CARLA simulator, one should reportthe performance in CARLA and NoCrash benchmarks."
Interpretability
In order to debug the model and interpret it's failures, interpretatbility is an important goal of the model. Methods for this are visual saliency (shown below), intermediate representatios and auxiliary outputs. Auxiliary outputs can be used to optimize the intermediate representations, which in turn feeds back into the main and task and improves it's workings.

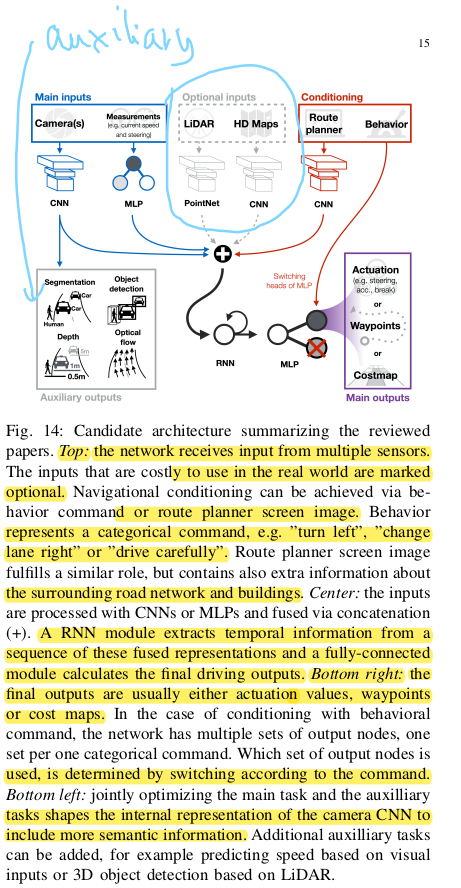
Example Architecture :
Based on the most promising end-to-end approaches today, the authors propose this following, theoretic architecutre which has not been implemented yet. The key in an actual implementation would be the fusion of the different neural network outputs.
Challenges and Conclusion
In order to drive safely in the real world, the long tail of edge case has to be handled as by the model. It will be important to find these rare scenarios and improve upon them. Data sampling techniques which emphasize on high loss examples ("When you sort your dataset descending by loss you are guaranteed to find something unexpected, strange and helpful." - Andrej Karpathy) will be the key for data engineering , by "massaging" the data rare data points can be found and handled correctly. While simulation will play an increasingly more important role due it's advantages for behavior reflex development, success in simulation does not guarantee success in real-world testing.
References
$[1]$ Felipe Codevilla, Eder Santana, Antonio M López, and Adrien Gaidon.
Exploring the limitations of behavior cloning for autonomous driving.
arXiv preprint arXiv:1904.08980, 2019
$[2]$ Felipe Codevilla, Matthias Miiller, Antonio López, Vladlen Koltun,
and Alexey Dosovitskiy. End-to-end driving via conditional imitation
learning. In 2018 IEEE International Conference on Robotics and
Automation (ICRA), pages 1–9. IEEE, 2018.
$[3]$ Mayank Bansal, Alex Krizhevsky, and Abhijit Ogale. Chauffeurnet:
Learning to drive by imitating the best and synthesizing the worst.
arXiv preprint arXiv:1812.03079, 2018.
$[4]$ Stéphane Ross, Geoffrey Gordon, and Drew Bagnell. A reduction of
imitation learning and structured prediction to no-regret online learning.
In Proceedings of the fourteenth international conference on artificial
intelligence and statistics, pages 627–635, 2011.
$[5]$ Sauhaarda Chowdhuri, Tushar Pankaj, and Karl Zipser. Multinet: Multi-
modal multi-task learning for autonomous driving. In 2019 IEEE
Winter Conference on Applications of Computer Vision (WACV), pages
1496–1504. IEEE, 2019.
$[6]$ Matthias Müller, Alexey Dosovitskiy, Bernard Ghanem, and Vladlen
Koltun. Driving policy transfer via modularity and abstraction. arXiv
preprint arXiv:1804.09364, 2018.
$[7]$ Xinlei Pan, Yurong You, Ziyan Wang, and Cewu Lu. Virtual to
real reinforcement learning for autonomous driving. arXiv preprint
arXiv:1704.03952, 2017.
$[8]$ Alex Bewley, Jessica Rigley, Yuxuan Liu, Jeffrey Hawke, Richard
Shen, Vinh-Dieu Lam, and Alex Kendall. Learning to drive from
simulation without real world labels. In 2019 International Conference
on Robotics and Automation (ICRA), pages 4818–4824. IEEE, 2019.
$[9]$ Brady Zhou, Philipp Krähenbühl, and Vladlen Koltun. Does computer
vision matter for action? arXiv preprint arXiv:1905.12887, 2019.
$[10]$ Felipe Codevilla, Eder Santana, Antonio M López, and Adrien Gaidon.
Exploring the limitations of behavior cloning for autonomous driving.
arXiv preprint arXiv:1904.08980, 2019