Efficient Det paper summary
Efficient Object Detection based on NAS, Path Aggregation and weighted feature fusion
What did the authors want to achieve ?
Recently, the SOTA in high accuracy in the fields of object detection and semantic segmentation were mostly achieved by scaling up architectures (e.g. AmoebaNet and NAS-FPN). These models are not easily deployable, especially in runtime/compute constrained applications such as autonomous driving. While existing worked has achieved faster rutime through one-stage/anchor-free detectors or model compression, they usually sacrifice accuracy for runtime. The goal is therefore to create an architecture that combines the best of both worlds, and achieve both high accuracy and better efficiency. The authors consider a wide range of compute that someone might have at hand during inference (3B to 300B FLOPS).
Methods
Challenges
The authors define 2 main challenges :
1) efficient multi-scale feature fusion
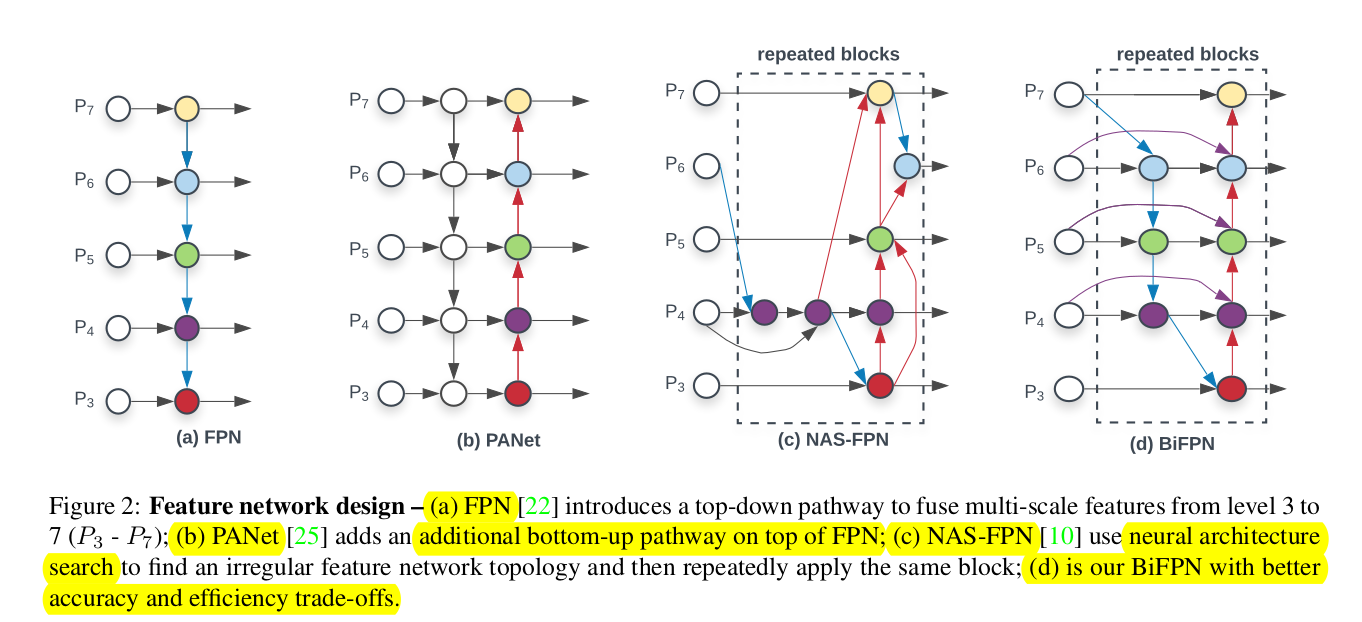
The authors do consider recent developments like PANet and NAS-FPN (both improvments of the original FPN approach). Most of these works only sum up the features without weighting them, even though the resolutions are different. That's why the authors of the paper propose a weighted bi-directional feature pyramid network (BiFPN), it introduces weights that can learn the importance of a different input features. It does this while also applying top-down and bottom-up bath augmentation as proposed in the PANet paper.
2) model scaling
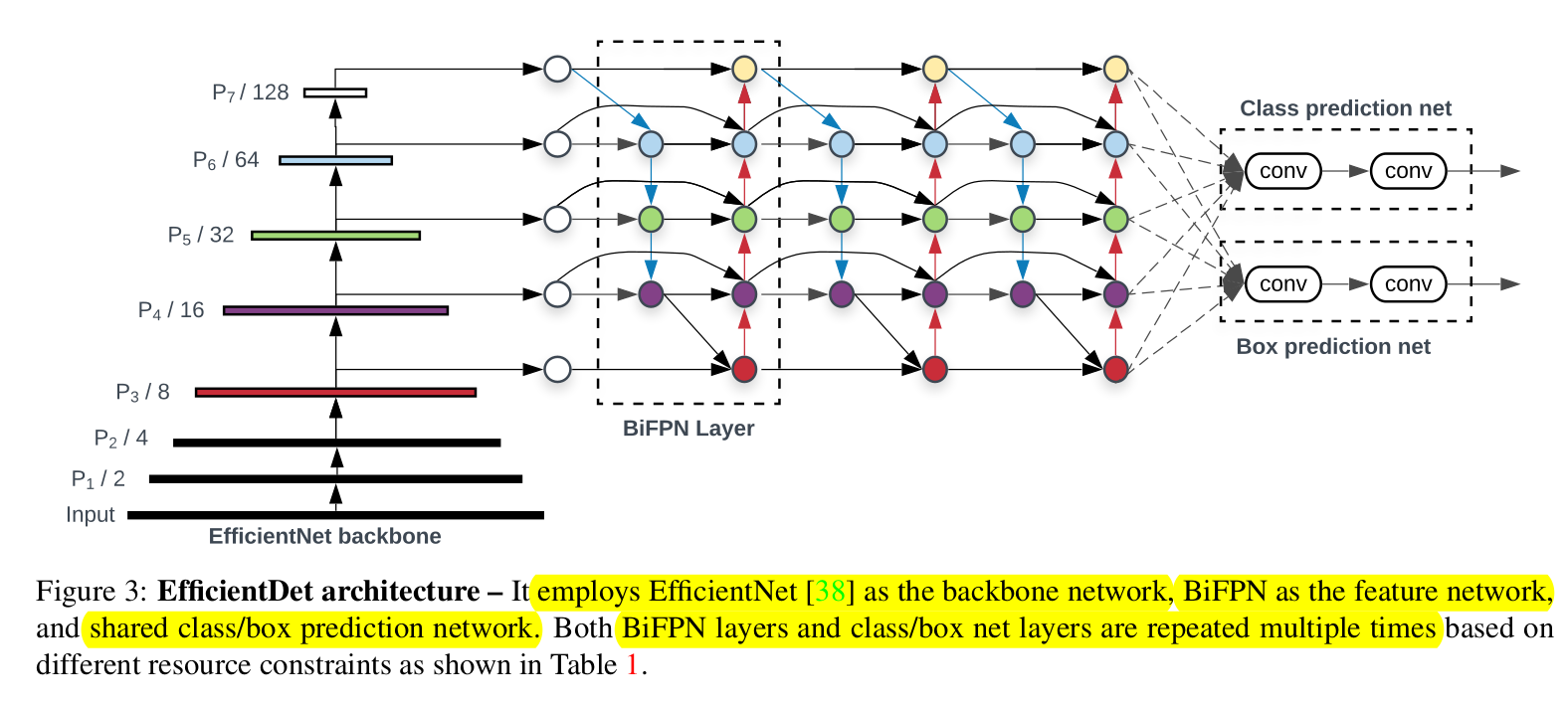
In the past, the main method to improve performance, was using larger and therefore more powerful backbones. In this paper the authors use NAS to jointly scale resolution of the input, depth and width of the net as well as sclaing the feature network and box/class prediction network. It thus follows the ideas of EfficientNet, which also turns out to be their backbone choice. The architectures that are proposed is therefore a combo of EfficientNet, BiPFN and compound scaling. These models are called EfficientDet, in honor of their Backbone.
 $Figure$ $1$
$Figure$ $1$
BiFPN
Problem
BiFPN aims to aggregate features at different resolutions, as FPN-ish methods downscale the feature level with a resolution of $1/2^{i}$ ($i$ being the layer number) , up-/downsampling is used in order to match features of different resolution.
Cross-Scale Connections
In their research the authors compare PANet (introduces bottom-up aggregation) with FPN and NAS-FPN and find that PANet achieves the best accuracy at the cost of some compute overhead. The authors improve upon these cross-scale connections by removing and thereby simplifying nodes with only one input edge, as these have less contribution to the feature net. Secondly they connect an extra edge from input to output node if they are at the same level (fusion with low compute cost), also see $Figure$ $1$. Furthermore, each bidirectional layer (top-down and bottom-up bath) is repeated multiple times to enable higher level fusion. For concrete implementation details (# of layers), refer to section 4.2 in the paper.
Weighted Feature Fusion
As explained earlier, the different resolutions that the feature maps have should be considered and therefore weithed during aggregation. In this work the authors use Pyramid Attention Network, which uses global self-attention upsampling to recover the location of the pixels. In order to weigh each input seperately, an additional learnable weight is added for each input. The authors consider three different fusion approaches :
1) Unbounded Fusion : $0 = \sum\limits_{i} w_{i} * I_{i}$ => could lead to instability, so weight norm is applied here
2) Softmax-based function : $O = \sum\limits_{i} \dfrac{e^{w_{i}}}{\sum\limits_{j} e^{w_{j}}} * I_{i}$
=> here the idea is to normalize the probablities between 0 and 1, weighting the importance of each input that way. However the softmax introduces extra slowdown on the GPU hardware, so 3) is proposed :
3) Fast normalized fusion : $O = \sum\limits_{i} \dfrac{w_{i}}{\sum\limits_{j} {w_{j}} + \epsilon} * I_{i}$
This function has the same learning charaterstics as 2), but it runs about 30% faster on GPU Depthwise sep. convs are used for better runtime.
Architecture
 $Figure$ $2$
$Figure$ $2$
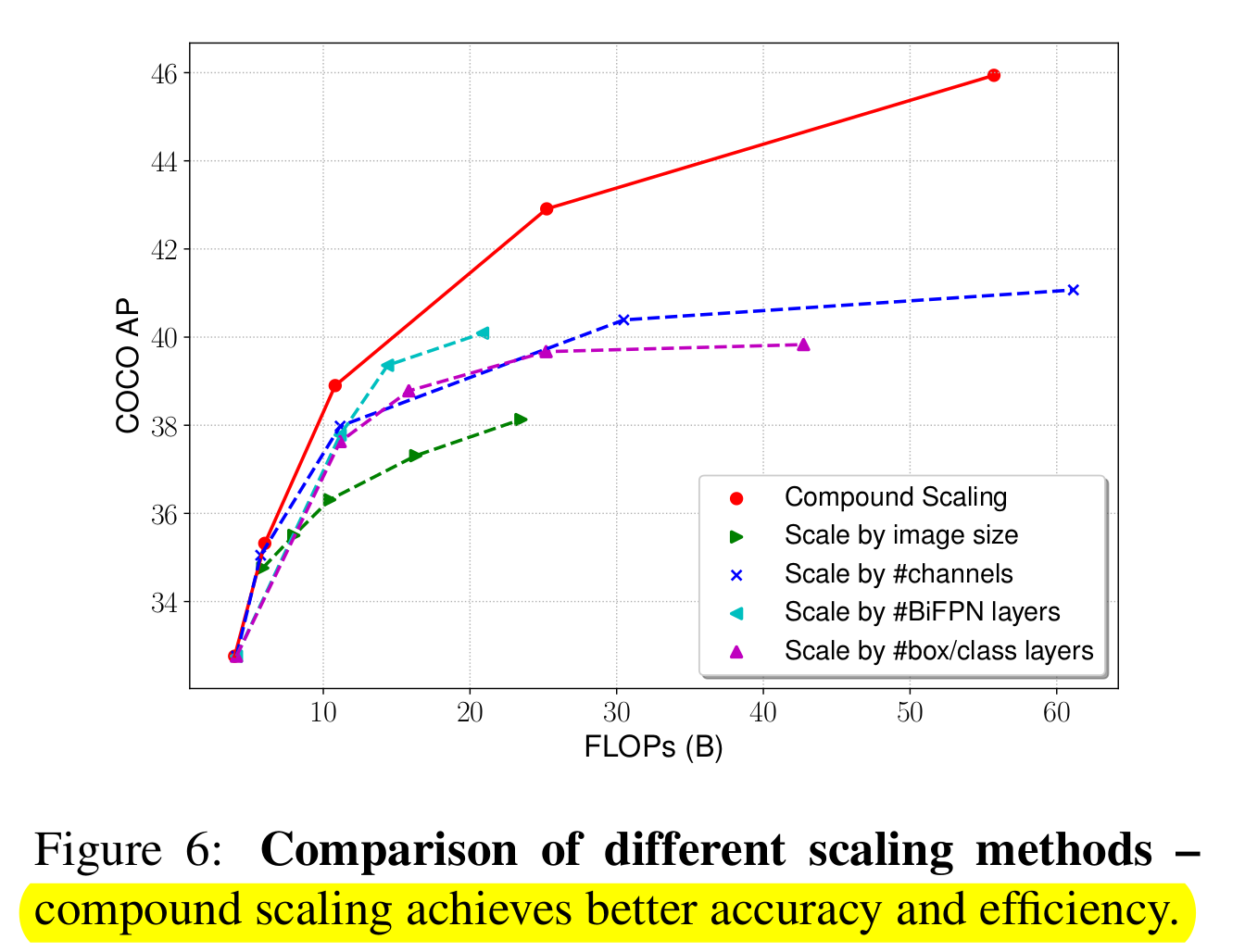
To create the final architecture a new compound scaling method is introduced which scales Backbone,BiFPN, class/box net and resolution jointly. A heuristics used as object detectors have even more possible configs as classification nets.
Backbone
In order to use ImageNet pretraining, the checkpoints of EfficientNet-B0 to B6 are used.
BiFPN Net
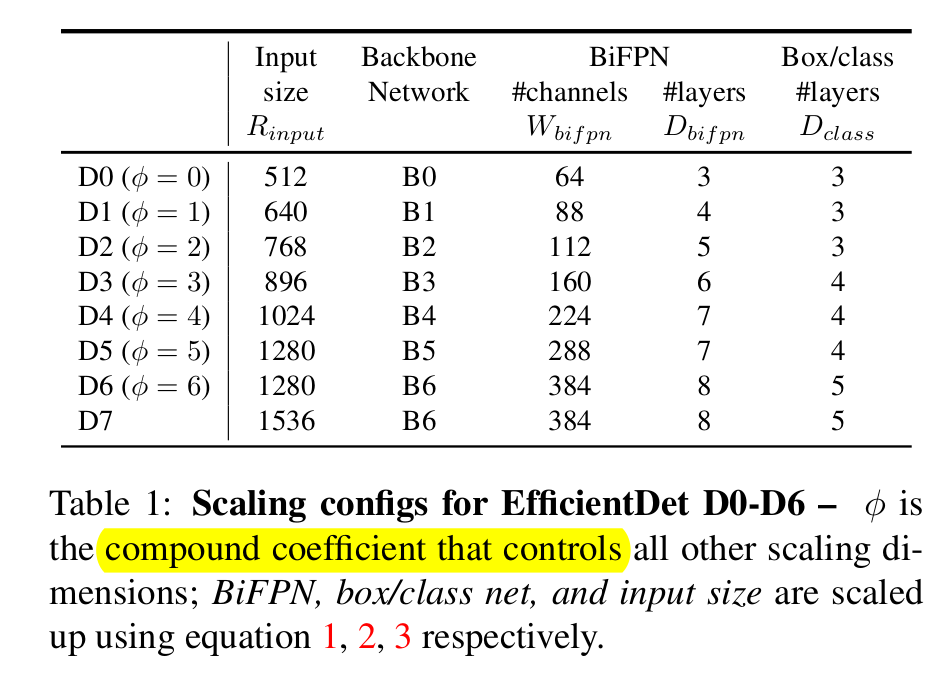
The BiFPN depth is linearly increased. The width is scaled exponentially, a grid search is done and 1.35 is used as a base :
$W_{BiFPN} = 64 * (1.35^{\theta})$
$D_{BiFPN} = 3 + \theta$
Box/class prediction network
Width is fixed to be same as BiFPN, but depth is increased differently : $D_{box} = D_{class} = 3 + [\theta/3]$
Image Resolution
Image res. is increased using equation : $R_{input} = 512 + \theta * 128$
128 is used as the features are used in level 3-7 and $2^{7} = 128$
Heuristics based scaling might not be optimal and could be improved.
The scaling results can be seen below :
The advantage of compound scaling is shown in $Figure$ $2$.
Some Implementation Details
- SGD with momentum 0.9 and weight decay 4e-5
- Synch BN w/BN decay of 0.99 end epsilon 1e-3
- swish activation with weight decay of 0.9998
- focal-loss with α = 0.25 and γ = 1.5, and aspect ratio {1/2, 1, 2}
- RetinaNnet preprocessing with training-time flip- ping and scaling
- soft NMS is used for D7, standard NMS for the others
Results
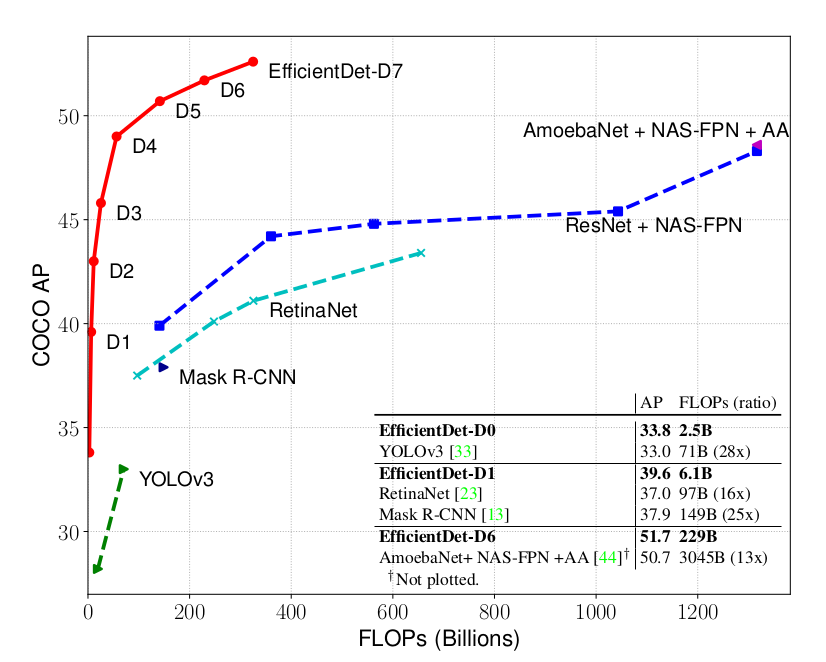
As the graph above shows, EfficientDet-D0 performs about on par with YOLOv3. It does use 28x fewer flops, which does not directly show in the runtime (also due to the optimized TensorRT implementation that YOLOv3 uses). Overall it is about 4-9x smaller and 13-42x less FLOP hungry than other detectors. In total they are about 4.1x faster on GPU and even 10x faster on CPU. This is probably due to the fact that the CPU can not hide the extra compute requierements in FLOPS as efficiently as the latency hiding GPU architecture.
The authors compete on a Segmentation task and outperform DeepLabV3+ by 1.7% on COCO Segmentation with 9.8x fewer FLOPS.