Summary LSUV Paper
<a href='https://arxiv.org/abs/1511.06422) suggests a novel initialization technique that allows the initalization of deep architectures wrt to other activations than ReLU (focus of Kaiming init'>All you need is a good init</a>
Key elements
LSUV extends orthogonal initalization and consists of two steps :
1) Fill the weights with Gaussian noise with unit variance
2) Decompose to orthonormal basis with QR or SVD decomposition and replace the weights with one of the components.
LSUV then estimates the variance of each convolution and inner product layer, the variance is scaled to equal one. It is worth mentioning that the batch size is neglactable in wide margins. In total LSUV can be seen as orthonormal initialization with batch norm applied at the first mini-batch. The orthonormal initalization of weights matrices de-correlates layer activations, a batch norm similarity is the unit variance normalization procedure. When compared to traditional batch norm, the results are sufficient and computationally more efficient. (Batch Norm adds about 30% in compute complexity to the system).It is not always possible to normalize the variance with the desired precision due to inconsistencies in data variations.
 The pseudocode for LSUV can be seen above, in order to restrict the number of maximum trials (avoid infinite loops) a $T_{max}$ is set. 1-5 iterations are required for the desired variance.
The pseudocode for LSUV can be seen above, in order to restrict the number of maximum trials (avoid infinite loops) a $T_{max}$ is set. 1-5 iterations are required for the desired variance.
Implementation
An implementation tutorial, powered by fastai can be found here.
Results and Conclusion
CIFAR 10/100
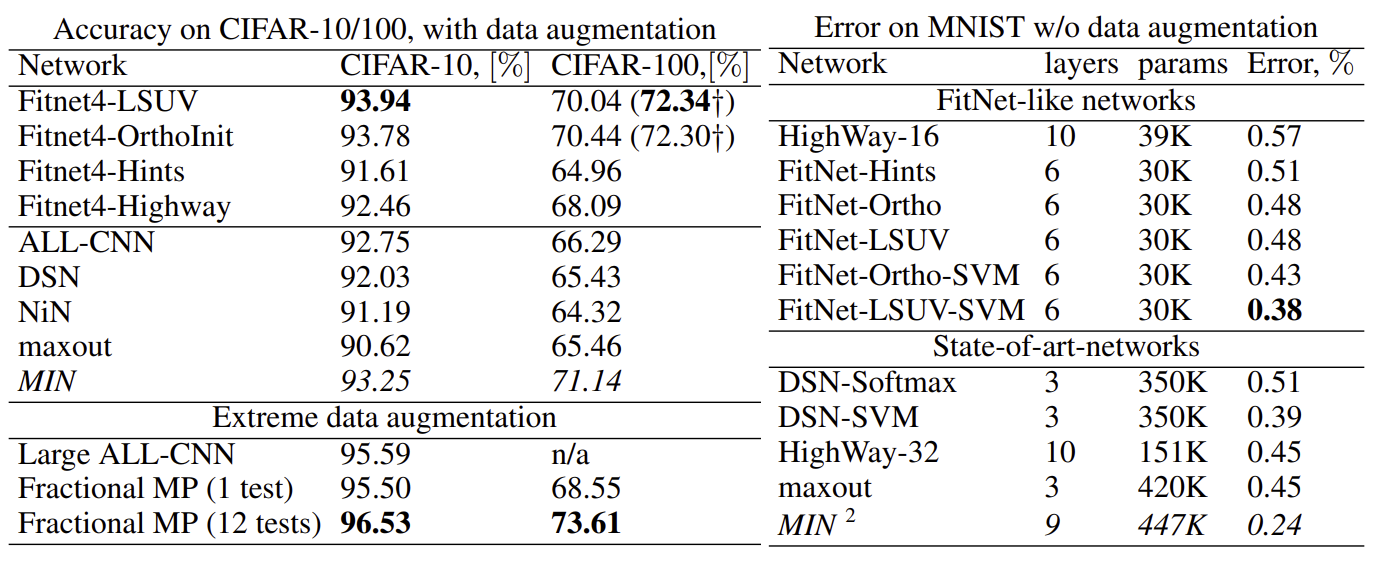
As we can see the FitNet with LSUV outperforms other techniques, but is virtually the same as orthonormal initalization. SGD was used with a learning rate of 0.01 and weight decay @ epoch 10/150/200 for 230 epochs in total.
Analysis of empircal results
For FitNet-1 the authors did not experience any problems with any of the activation functions that they used (ReLU,maxout,tanh) optimizers (SGD,RMSProp) or initalizaton techniques (Xavier,MSRA,Ortho,LSUV). This is most likely due to the fact that CNNs tolerate a wide range of mediocre inits, only the training time increases. However FitNet-4 was much more difficult to optimize.
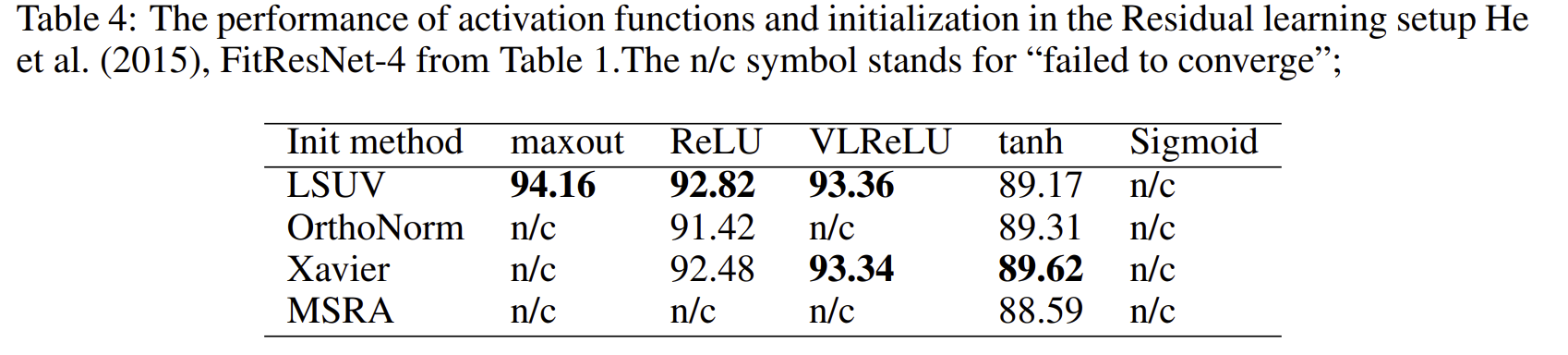
Training a FitResNet-4 on CIFAR-10, which tests the initalization with ResNet training "out-of-the-box", LSUV is proven to be the only initalization technique that leads all nets to converge regardless of the activation function that was used :
LSUV compared to Batch Norm
LSUV can be seen as batch norm of layer output done before the start of training. The authors also prove that putting batch norm after the activation function is proven to work for FitNet-4.
ImageNet training
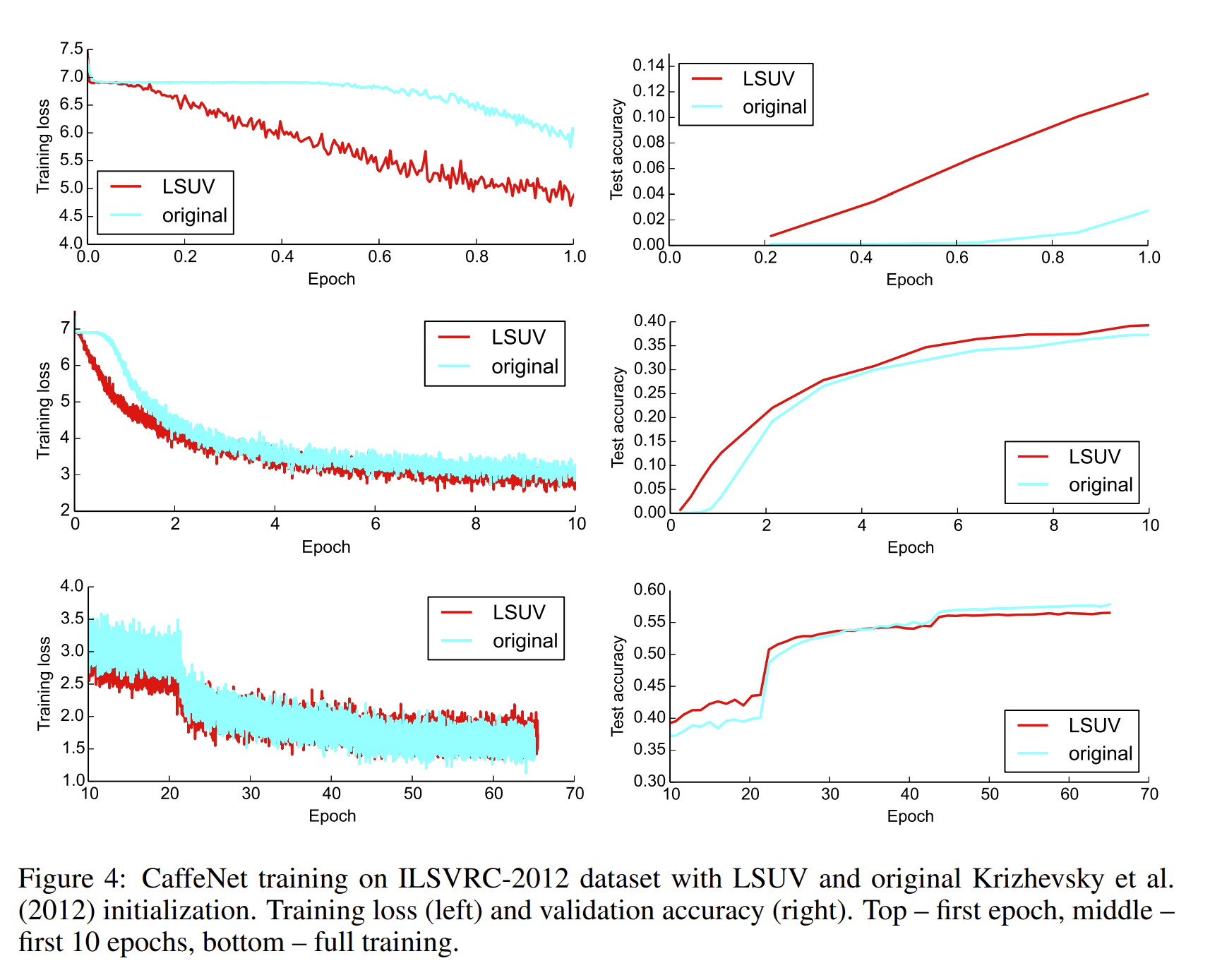 When training on ImageNet the authors found out that, LSUV reduces the starting flat-loss time from 0.5 epochs to 0.05 for CaffeNet. It also converges faster in the beginning, but is then overtaken by a standard CaffeNet architecture at the 30th epoch and has a 1.3% lower precision in the end. The authors of the paper do not have any explanation for this empirical phenomenon. Especially since in contrast GoogLeNet performed better (0.68 compared to 0.672)
When training on ImageNet the authors found out that, LSUV reduces the starting flat-loss time from 0.5 epochs to 0.05 for CaffeNet. It also converges faster in the beginning, but is then overtaken by a standard CaffeNet architecture at the 30th epoch and has a 1.3% lower precision in the end. The authors of the paper do not have any explanation for this empirical phenomenon. Especially since in contrast GoogLeNet performed better (0.68 compared to 0.672)
LSUV Timing
The significant part of LSUV is SVD-decomposition of the weight matrices. The compute overhead on top of generating the Gaussian noise (that's almost instant) is about 3.5 Minutes for CaffeNet, which is very small compared to total training time.
The authors state that the experiments confirm the finding of Romero et al. (2015) that very thin, thus fast and low in parameters, but deep networks obtain comparable or even better performance than wider, but shallower nets. LSUV is fast and the results are almost state-of-the art.