Fastai Course DL from the Foundations LSTM RNN
Implementing an own LSTM RNN with PyTorch (Lesson 5 Part 6)



Fastai AWD-LSTM
- This Post is based on the Notebok by the Fastai Course Part2
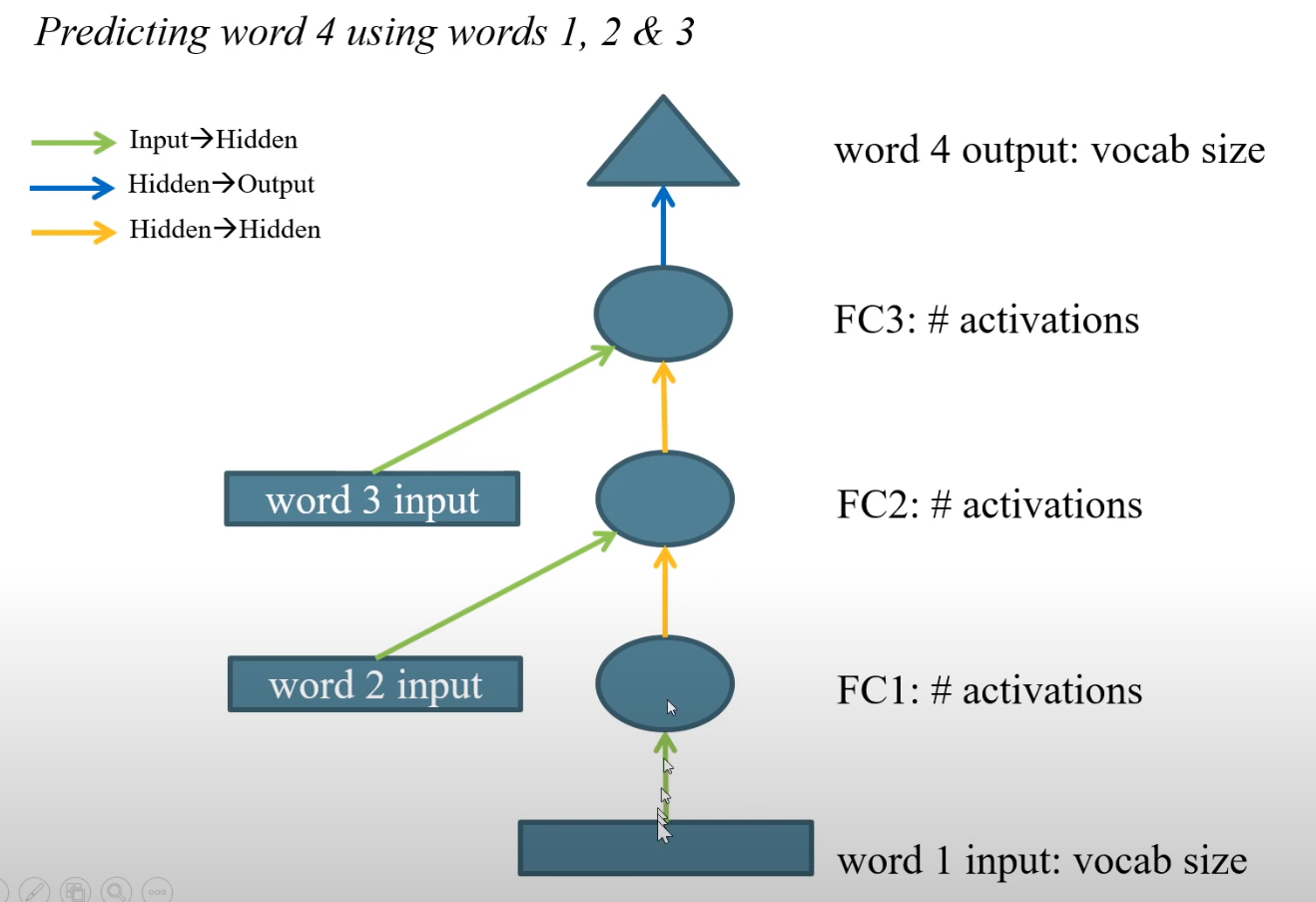
In order to avoid writing many layers (number of layers = number of docs for example), that is why a for loop is used.
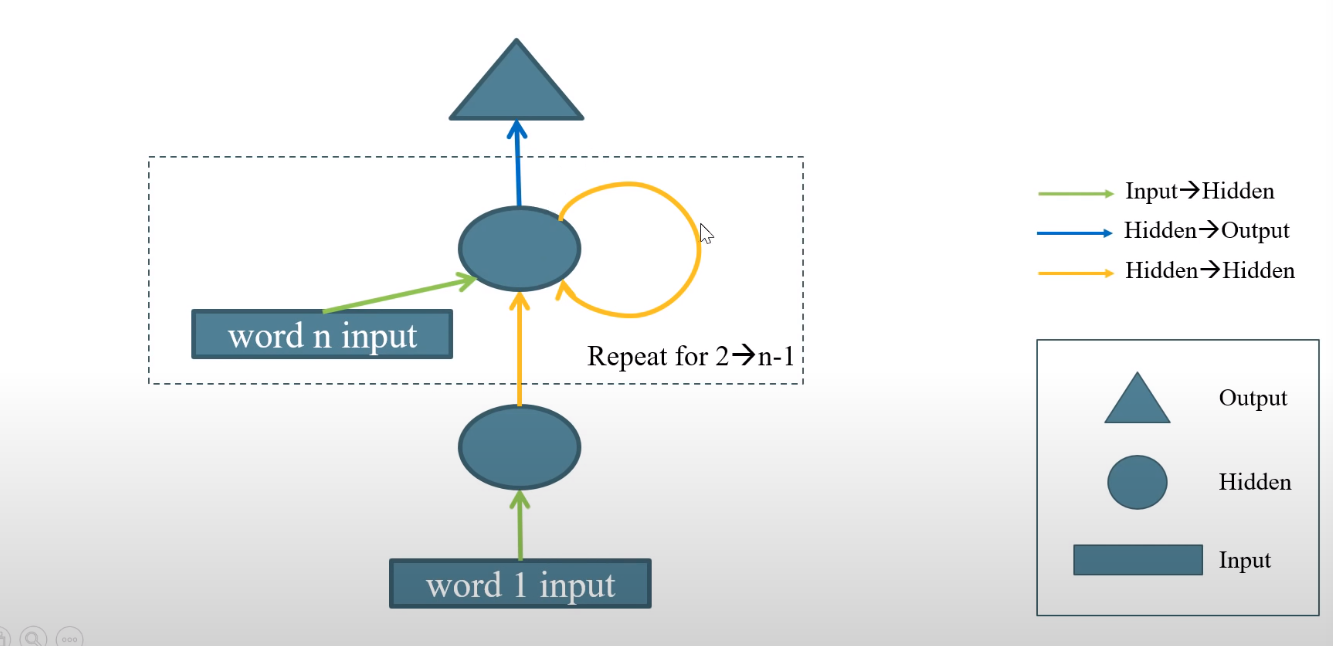
The same weight matrices are used, so for loops are valid. In order to avoid vanishing gradients for large sequences, LSTMs or GRUs are used.
#collapse
%load_ext autoreload
%autoreload 2
%matplotlib inline
#collapse
from exp.nb_12 import *
#collapse
path = datasets.untar_data(datasets.URLs.IMDB)
We have to preprocess the data again to pickle it because if we try to load the previous SplitLabeledData with pickle, it will complain some of the functions aren't in main.
#collapse
il = TextList.from_files(path, include=['train', 'test', 'unsup'])
sd = SplitData.split_by_func(il, partial(random_splitter, p_valid=0.1))
#collapse
proc_tok,proc_num = TokenizeProcessor(max_workers=8),NumericalizeProcessor()
#collapse
ll = label_by_func(sd, lambda x: 0, proc_x = [proc_tok,proc_num])
#collapse
pickle.dump(ll, open(path/'ll_lm.pkl', 'wb'))
pickle.dump(proc_num.vocab, open(path/'vocab_lm.pkl', 'wb'))
#collapse
ll = pickle.load(open(path/'ll_lm.pkl', 'rb'))
vocab = pickle.load(open(path/'vocab_lm.pkl', 'rb'))
#collapse
bs,bptt = 64,70
data = lm_databunchify(ll, bs, bptt)
Before explaining what an AWD LSTM is, we need to start with an LSTM. RNNs were covered in part 1, if you need a refresher, there is a great visualization of them on this website.
We need to implement those equations (where $\sigma$ stands for sigmoid):
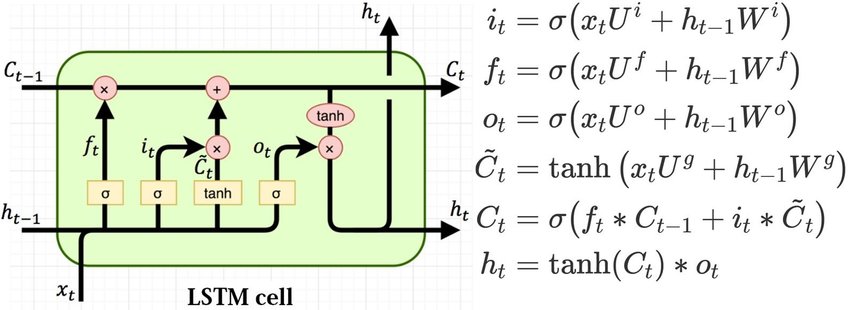 (picture from Understanding LSTMs by Chris Olah.)
(picture from Understanding LSTMs by Chris Olah.)
If we want to take advantage of our GPU, it's better to do one big matrix multiplication than four smaller ones. So we compute the values of the four gates all at once. Since there is a matrix multiplication and a bias, we use nn.Linear to do it.
We need two linear layers: one for the input and one for the hidden state.
#collapse_show
class LSTMCell(nn.Module):
def __init__(self, ni, nh):
super().__init__()
self.ih = nn.Linear(ni,4*nh)
self.hh = nn.Linear(nh,4*nh)
def forward(self, input, state):
h,c = state
#One big multiplication for all the gates is better than 4 smaller ones
gates = (self.ih(input) + self.hh(h)).chunk(4, 1)
ingate,forgetgate,outgate = map(torch.sigmoid, gates[:3])
cellgate = gates[3].tanh()
c = (forgetgate*c) + (ingate*cellgate)
h = outgate * c.tanh()
return h, (h,c)
Then an LSTM layer just applies the cell on all the time steps in order.
#collapse_show
class LSTMLayer(nn.Module):
def __init__(self, cell, *cell_args):
super().__init__()
self.cell = cell(*cell_args)
def forward(self, input, state):
inputs = input.unbind(1)
outputs = []
for i in range(len(inputs)):
out, state = self.cell(inputs[i], state)
outputs += [out]
return torch.stack(outputs, dim=1), state
Now let's try it out and see how fast we are. We only measure the forward pass.
#collapse_show
lstm = LSTMLayer(LSTMCell, 300, 300)
#collapse_show
x = torch.randn(64, 70, 300)
h = (torch.zeros(64, 300),torch.zeros(64, 300))
CPU
#collapse_show
%timeit -n 10 y,h1 = lstm(x,h)
#collapse_show
lstm = lstm.cuda()
x = x.cuda()
h = (h[0].cuda(), h[1].cuda())
#collapse_show
def time_fn(f):
f()
torch.cuda.synchronize()
CUDA
#collapse_show
f = partial(lstm,x,h)
time_fn(f)
#collapse_show
%timeit -n 10 time_fn(f)
Let's compare with PyTorch!
#collapse_show
lstm = nn.LSTM(300, 300, 1, batch_first=True)
#collapse_show
x = torch.randn(64, 70, 300)
h = (torch.zeros(1, 64, 300),torch.zeros(1, 64, 300))
CPU
#collapse_show
%timeit -n 10 y,h1 = lstm(x,h)
#collapse_show
lstm = lstm.cuda()
x = x.cuda()
h = (h[0].cuda(), h[1].cuda())
#collapse_show
f = partial(lstm,x,h)
time_fn(f)
GPU
#collapse_show
%timeit -n 10 time_fn(f)
So our version is running at almost the same speed on the CPU. However, on the GPU, PyTorch uses CuDNN behind the scenes that optimizes greatly the for loop.
#collapse
import torch.jit as jit
from torch import Tensor
We have to write everything from scratch to be a bit faster, so we don't use the linear layers here.
#collapse_show
class LSTMCell(jit.ScriptModule):
def __init__(self, ni, nh):
super().__init__()
self.ni = ni
self.nh = nh
self.w_ih = nn.Parameter(torch.randn(4 * nh, ni))
self.w_hh = nn.Parameter(torch.randn(4 * nh, nh))
self.bias_ih = nn.Parameter(torch.randn(4 * nh))
self.bias_hh = nn.Parameter(torch.randn(4 * nh))
@jit.script_method
def forward(self, input:Tensor, state:Tuple[Tensor, Tensor])->Tuple[Tensor, Tuple[Tensor, Tensor]]:
hx, cx = state
gates = (input @ self.w_ih.t() + self.bias_ih +
hx @ self.w_hh.t() + self.bias_hh)
ingate, forgetgate, cellgate, outgate = gates.chunk(4, 1)
ingate = torch.sigmoid(ingate)
forgetgate = torch.sigmoid(forgetgate)
cellgate = torch.tanh(cellgate)
outgate = torch.sigmoid(outgate)
cy = (forgetgate * cx) + (ingate * cellgate)
hy = outgate * torch.tanh(cy)
return hy, (hy, cy)
#collapse_show
class LSTMLayer(jit.ScriptModule):
def __init__(self, cell, *cell_args):
super().__init__()
self.cell = cell(*cell_args)
@jit.script_method
def forward(self, input:Tensor, state:Tuple[Tensor, Tensor])->Tuple[Tensor, Tuple[Tensor, Tensor]]:
inputs = input.unbind(1)
outputs = []
for i in range(len(inputs)):
out, state = self.cell(inputs[i], state)
outputs += [out]
return torch.stack(outputs, dim=1), state
#collapse_show
lstm = LSTMLayer(LSTMCell, 300, 300)
#collapse_show
x = torch.randn(64, 70, 300)
h = (torch.zeros(64, 300),torch.zeros(64, 300))
#collapse_show
%timeit -n 10 y,h1 = lstm(x,h)
#collapse_show
lstm = lstm.cuda()
x = x.cuda()
h = (h[0].cuda(), h[1].cuda())
#collapse_show
f = partial(lstm,x,h)
time_fn(f)
#collapse_show
%timeit -n 10 time_fn(f)
With jit, we almost get to the CuDNN speed!
We want to use the AWD-LSTM from Stephen Merity et al.. First, we'll need all different kinds of dropouts. Dropout consists into replacing some coefficients by 0 with probability p. To ensure that the average of the weights remains constant, we apply a correction to the weights that aren't nullified of a factor 1/(1-p) (think of what happens to the activations if you want to figure out why!)
We usually apply dropout by drawing a mask that tells us which elements to nullify or not:
#collapse_show
def dropout_mask(x, sz, p):
return x.new(*sz).bernoulli_(1-p).div_(1-p)
#collapse_show
x = torch.randn(10,10)
mask = dropout_mask(x, (10,10), 0.5); mask
Once with have a dropout mask mask, applying the dropout to x is simply done by x = x * mask. We create our own dropout mask and don't rely on pytorch dropout because we do not want to nullify all the coefficients randomly: on the sequence dimension, we will want to have always replace the same positions by zero along the seq_len dimension.
#collapse_show
(x*mask).std(),x.std()
Inside a RNN, a tensor x will have three dimensions: bs, seq_len, vocab_size. Recall that we want to consistently apply the dropout mask across the seq_len dimension, therefore, we create a dropout mask for the first and third dimension and broadcast it to the seq_len dimension.
#collapse_show
class RNNDropout(nn.Module):
def __init__(self, p=0.5):
super().__init__()
self.p=p
def forward(self, x):
if not self.training or self.p == 0.: return x
m = dropout_mask(x.data, (x.size(0), 1, x.size(2)), self.p)
return x * m
#collapse_show
dp = RNNDropout(0.3)
tst_input = torch.randn(3,3,7)
tst_input, dp(tst_input)
WeightDropout is dropout applied to the weights of the inner LSTM hidden to hidden matrix. This is a little hacky if we want to preserve the CuDNN speed and not reimplement the cell from scratch. We add a parameter that will contain the raw weights, and we replace the weight matrix in the LSTM at the beginning of the forward pass.
#collapse_show
import warnings
WEIGHT_HH = 'weight_hh_l0'
class WeightDropout(nn.Module):
def __init__(self, module, weight_p=[0.], layer_names=[WEIGHT_HH]):
super().__init__()
self.module,self.weight_p,self.layer_names = module,weight_p,layer_names
for layer in self.layer_names:
#Makes a copy of the weights of the selected layers.
w = getattr(self.module, layer)
self.register_parameter(f'{layer}_raw', nn.Parameter(w.data))
self.module._parameters[layer] = F.dropout(w, p=self.weight_p, training=False)
def _setweights(self):
for layer in self.layer_names:
raw_w = getattr(self, f'{layer}_raw')
self.module._parameters[layer] = F.dropout(raw_w, p=self.weight_p, training=self.training)
def forward(self, *args):
self._setweights()
with warnings.catch_warnings():
#To avoid the warning that comes because the weights aren't flattened.
warnings.simplefilter("ignore")
return self.module.forward(*args)
Let's try it!
#collapse_show
module = nn.LSTM(5, 2)
dp_module = WeightDropout(module, 0.4)
getattr(dp_module.module, WEIGHT_HH)
It's at the beginning of a forward pass that the dropout is applied to the weights.
#collapse_show
tst_input = torch.randn(4,20,5)
h = (torch.zeros(1,20,2), torch.zeros(1,20,2))
x,h = dp_module(tst_input,h)
getattr(dp_module.module, WEIGHT_HH)
EmbeddingDropout applies dropout to full rows of the embedding matrix.
#collapse_show
class EmbeddingDropout(nn.Module):
"Applies dropout in the embedding layer by zeroing out some elements of the embedding vector."
def __init__(self, emb, embed_p):
super().__init__()
self.emb,self.embed_p = emb,embed_p
self.pad_idx = self.emb.padding_idx
if self.pad_idx is None: self.pad_idx = -1
def forward(self, words, scale=None):
if self.training and self.embed_p != 0:
size = (self.emb.weight.size(0),1)
mask = dropout_mask(self.emb.weight.data, size, self.embed_p)
masked_embed = self.emb.weight * mask
else: masked_embed = self.emb.weight
if scale: masked_embed.mul_(scale)
return F.embedding(words, masked_embed, self.pad_idx, self.emb.max_norm,
self.emb.norm_type, self.emb.scale_grad_by_freq, self.emb.sparse)
#collapse_show
enc = nn.Embedding(100, 7, padding_idx=1)
enc_dp = EmbeddingDropout(enc, 0.5)
tst_input = torch.randint(0,100,(8,))
enc_dp(tst_input)
The main model is a regular LSTM with several layers, but using all those kinds of dropouts.
#collapse_show
def to_detach(h):
"Detaches `h` from its history."
return h.detach() if type(h) == torch.Tensor else tuple(to_detach(v) for v in h)
#collapse_show
class AWD_LSTM(nn.Module):
"AWD-LSTM inspired by https://arxiv.org/abs/1708.02182."
initrange=0.1
def __init__(self, vocab_sz, emb_sz, n_hid, n_layers, pad_token,
hidden_p=0.2, input_p=0.6, embed_p=0.1, weight_p=0.5):
super().__init__()
self.bs,self.emb_sz,self.n_hid,self.n_layers = 1,emb_sz,n_hid,n_layers
self.emb = nn.Embedding(vocab_sz, emb_sz, padding_idx=pad_token)
self.emb_dp = EmbeddingDropout(self.emb, embed_p)
self.rnns = [nn.LSTM(emb_sz if l == 0 else n_hid, (n_hid if l != n_layers - 1 else emb_sz), 1,
batch_first=True) for l in range(n_layers)]
self.rnns = nn.ModuleList([WeightDropout(rnn, weight_p) for rnn in self.rnns])
self.emb.weight.data.uniform_(-self.initrange, self.initrange)
self.input_dp = RNNDropout(input_p)
self.hidden_dps = nn.ModuleList([RNNDropout(hidden_p) for l in range(n_layers)])
def forward(self, input):
bs,sl = input.size()
if bs!=self.bs:
self.bs=bs
self.reset()
raw_output = self.input_dp(self.emb_dp(input))
new_hidden,raw_outputs,outputs = [],[],[]
for l, (rnn,hid_dp) in enumerate(zip(self.rnns, self.hidden_dps)):
raw_output, new_h = rnn(raw_output, self.hidden[l])
new_hidden.append(new_h)
raw_outputs.append(raw_output)
if l != self.n_layers - 1: raw_output = hid_dp(raw_output)
outputs.append(raw_output)
self.hidden = to_detach(new_hidden)
return raw_outputs, outputs
def _one_hidden(self, l):
"Return one hidden state."
nh = self.n_hid if l != self.n_layers - 1 else self.emb_sz
return next(self.parameters()).new(1, self.bs, nh).zero_()
def reset(self):
"Reset the hidden states."
self.hidden = [(self._one_hidden(l), self._one_hidden(l)) for l in range(self.n_layers)]
On top of this, we will apply a linear decoder. It's often best to use the same matrix as the one for the embeddings in the weights of the decoder.
#collapse_show
class LinearDecoder(nn.Module):
def __init__(self, n_out, n_hid, output_p, tie_encoder=None, bias=True):
super().__init__()
self.output_dp = RNNDropout(output_p)
self.decoder = nn.Linear(n_hid, n_out, bias=bias)
if bias: self.decoder.bias.data.zero_()
if tie_encoder: self.decoder.weight = tie_encoder.weight
else: init.kaiming_uniform_(self.decoder.weight)
def forward(self, input):
raw_outputs, outputs = input
output = self.output_dp(outputs[-1]).contiguous()
decoded = self.decoder(output.view(output.size(0)*output.size(1), output.size(2)))
return decoded, raw_outputs, outputs
#collapse_show
class SequentialRNN(nn.Sequential):
"A sequential module that passes the reset call to its children."
def reset(self):
for c in self.children():
if hasattr(c, 'reset'): c.reset()
And now we stack all of this together!
#collapse_show
def get_language_model(vocab_sz, emb_sz, n_hid, n_layers, pad_token, output_p=0.4, hidden_p=0.2, input_p=0.6,
embed_p=0.1, weight_p=0.5, tie_weights=True, bias=True):
rnn_enc = AWD_LSTM(vocab_sz, emb_sz, n_hid=n_hid, n_layers=n_layers, pad_token=pad_token,
hidden_p=hidden_p, input_p=input_p, embed_p=embed_p, weight_p=weight_p)
enc = rnn_enc.emb if tie_weights else None
return SequentialRNN(rnn_enc, LinearDecoder(vocab_sz, emb_sz, output_p, tie_encoder=enc, bias=bias))
tok_pad = vocab.index(PAD)
Now we can test this all works without throwing a bug.
#collapse_show
tst_model = get_language_model(len(vocab), 300, 300, 2, tok_pad)
tst_model = tst_model.cuda()
#collapse_show
x,y = next(iter(data.train_dl))
#collapse_show
z = tst_model(x.cuda())
We return three things to help with regularization: the true output (probabilities for each word), but also the activations of the encoder, with or without dropouts.
len(z)
decoded, raw_outputs, outputs = z
The decoded tensor is flattened to bs * seq_len by len(vocab):
decoded.size()
raw_outputs and outputs each contain the results of the intermediary layers:
#collapse_show
len(raw_outputs),len(outputs)
#collapse_show
[o.size() for o in raw_outputs], [o.size() for o in outputs]
We need to add a few tweaks to train a language model: first we will clip the gradients. This is a classic technique that will allow us to use a higher learning rate by putting a maximum value on the norm of the gradients.
#collapse_show
class GradientClipping(Callback):
def __init__(self, clip=None): self.clip = clip
def after_backward(self):
if self.clip: nn.utils.clip_grad_norm_(self.run.model.parameters(), self.clip)
Then we add an RNNTrainer that will do four things:
- change the output to make it contain only the
decodedtensor (for the loss function) and store theraw_outputsandoutputs - apply Activation Regularization (AR): we add to the loss an L2 penalty on the last activations of the AWD LSTM (with dropout applied)
- apply Temporal Activation Regularization (TAR): we add to the loss an L2 penalty on the difference between two consecutive (in terms of words) raw outputs
- trigger the shuffle of the LMDataset at the beginning of each epoch
#collapse_show
class RNNTrainer(Callback):
def __init__(self, α, β): self.α,self.β = α,β
def after_pred(self):
#Save the extra outputs for later and only returns the true output.
self.raw_out,self.out = self.pred[1],self.pred[2]
self.run.pred = self.pred[0]
def after_loss(self):
#AR and TAR
if self.α != 0.: self.run.loss += self.α * self.out[-1].float().pow(2).mean()
if self.β != 0.:
h = self.raw_out[-1]
if h.size(1)>1: self.run.loss += self.β * (h[:,1:] - h[:,:-1]).float().pow(2).mean()
def begin_epoch(self):
#Shuffle the texts at the beginning of the epoch
if hasattr(self.dl.dataset, "batchify"): self.dl.dataset.batchify()
Lastly we write a flattened version of the cross entropy loss and the accuracy metric.
#collapse_show
def cross_entropy_flat(input, target):
bs,sl = target.size()
return F.cross_entropy(input.view(bs * sl, -1), target.view(bs * sl))
def accuracy_flat(input, target):
bs,sl = target.size()
return accuracy(input.view(bs * sl, -1), target.view(bs * sl))
#collapse_show
emb_sz, nh, nl = 300, 300, 2
model = get_language_model(len(vocab), emb_sz, nh, nl, tok_pad, input_p=0.6, output_p=0.4, weight_p=0.5,
embed_p=0.1, hidden_p=0.2)
#collapse_show
cbs = [partial(AvgStatsCallback,accuracy_flat),
CudaCallback, Recorder,
partial(GradientClipping, clip=0.1),
partial(RNNTrainer, α=2., β=1.),
ProgressCallback]
#collapse_show
learn = Learner(model, data, cross_entropy_flat, lr=5e-3, cb_funcs=cbs, opt_func=adam_opt())
#collapse_show
learn.fit(1)