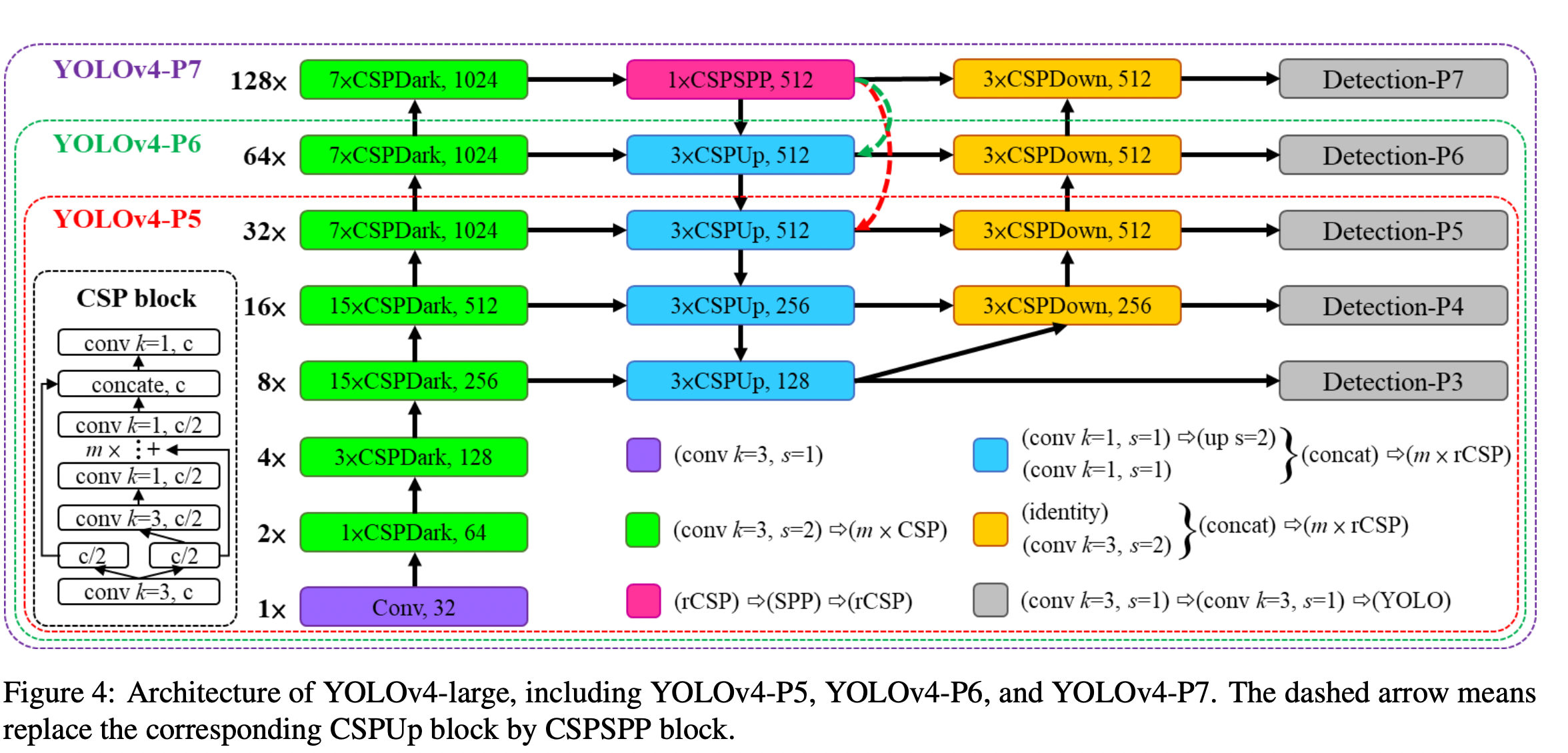
Methods/Structure
Scaling Larger Models
When looking at the compute cost of different layer types in relation to input resolution $\alpha$, number of layers $\beta$ and number of channels $\gamma$ the authors find the following :

Using CSP Connections, compute cost can be reduced to :
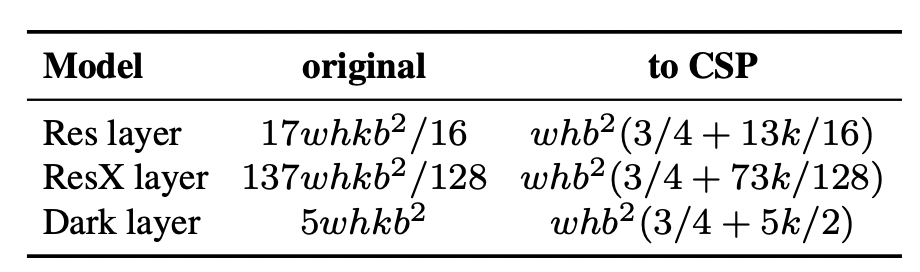
Further advantages of CSP are accuracy gains and faster inference, therefore no tradeoff exists.
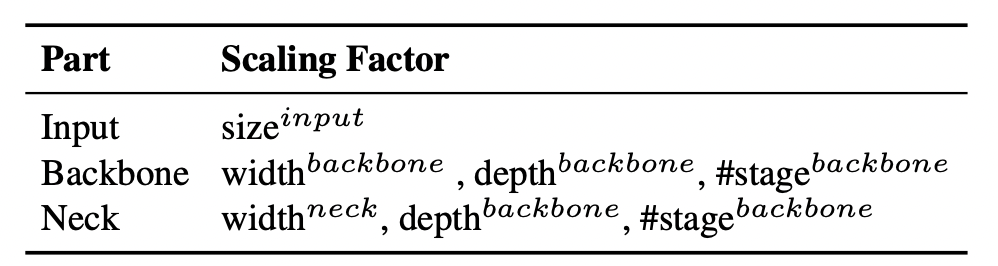
The different scaling factors for an object detection model are displayed in the table below :
"The biggest difference between image classification and object detection is that the former only needs to identify the category of the largest component in an image, while the lat- ter needs to predict the position and size of each object in an image."
This ability for a single stage object detector (the receptive field) is most accurately described by the stage. Higher stages are more suitable for predicting larger objects (FPN). The effect of the receptive field according to different parameters is shown below :

Scaling Models for Embedded Devices
The authors consider DRAM and inference speed and select a criteria for models that can run on lower end devices in real time. The criterion for this is a runtime that scales with at most $O(w*h*k*b^{2})$

Minimize/balance size of feature map
Because OSANet has a lower compute cost $O(max(whbg,whkb^{2}))$ than Dense Net $O(whgbk)$
The authors also emphasize on minimizing the feature maps. Feature maps have to be treated as a whole in terms of a block (Dense Net, ResNet Block). The feature that "Because the computational block of OSANet belongs to the PlainNet architecture, making CSPNet from any layer of a computational block can achieve the effect of gradient truncation" is exploited to efficiently partition the paths from $b+kg$ to $(b+kg)/2$. When hardware latency τ is considered, this results in : $ceil((b + kg)/2τ ) × τ$
Maintain the same number of channels after convolution
In terms of power consumption, memory access cost is also a large factor on embedded Hardware. It can be calculated as follows :
$MAC = hw(C_{in} + C_{out}) + KC_{in}C_{out}$
h,w, C (in and out) and K are height and width of feature map, the channel number of input and output, and the kernel size of the convolutional filter.

Minimize Convolutional Input/Output (CIO)
CIO can measure the DRAM in and output. When kg > b/2 CSPOSANET minimizes this according to:

Scaling
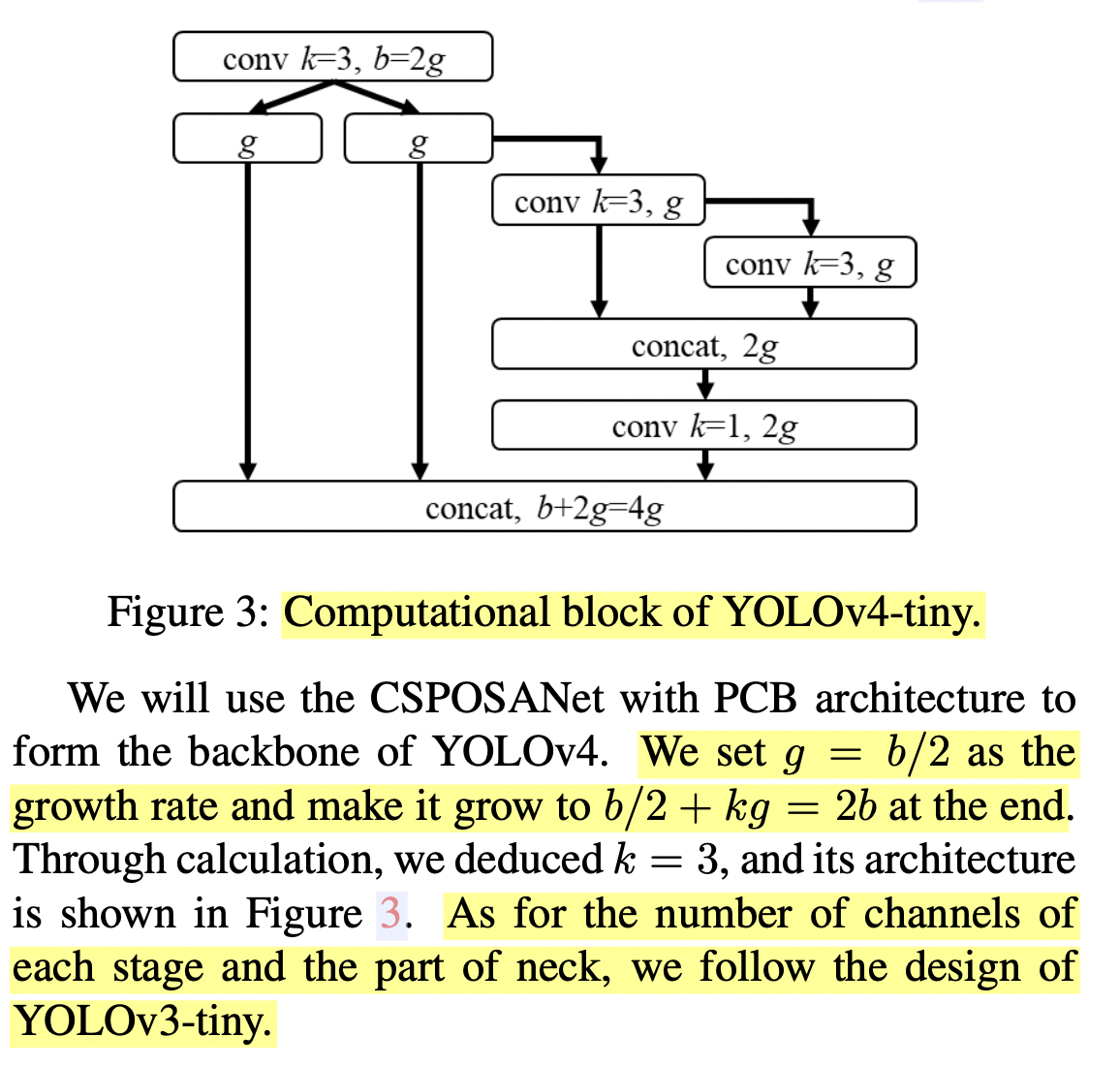
Backbone
"In the design of CSPDarknet53, the computation of down-sampling convolution for cross-stage process is not included in a residual block." That's why the CSPDarknet53 has a compute of whb2(9/4+3/4+5k/2). From the runtime analysis in the beginning, CSP Net only has a better runtime than CSPDarknet when k > 1. Therefore in order to keep a decent runtime, the first CSP stage is converted to a Darknet layer :
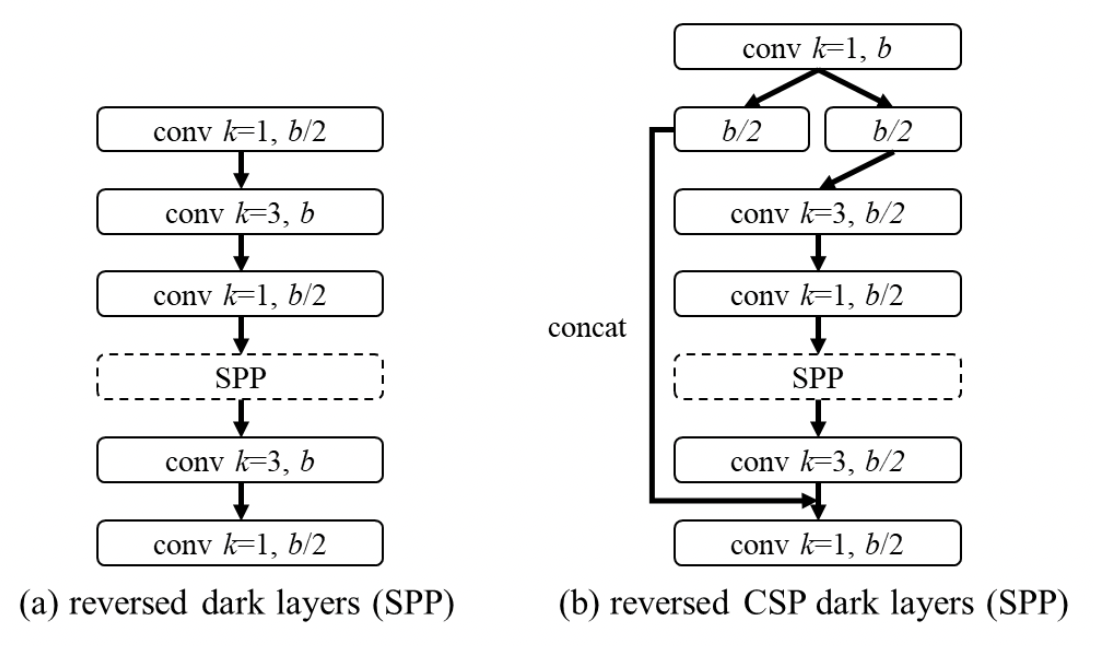
Neck
PANet Neck of Yolov4 is made 40% more compute efficient by CSPizing it." It mainly intagrates the features from different feature pyramids, and then passes through two sets of reversed Darknet residual layer without shortcut connections."
SPP
The SPP module is also kept inside of the CSP module analgous to the original approach.
Models
The scaling approach allows the creation of a tiny model and different large models.
For the large model, 3 different large models are created which are fully CSPized. YOLOv4-P5 can reach 60 FPS with the right width scaling factor. It outperforms EfficientDet-D5 slightly while being 1.9 times faster. The tiny version performs at speeds up to 290 FPS (Xavier AGX, FP16 in Tensorrt) and is more than real time capable.